PDFファイルの構造を知りたくてAdobe社から公開されているPDF 1.7の仕様書を少し読んだのですが、ボリュームが多く、英語で書かれていて理解が進みづらいと感じていました。
日本語の本とかないのかなと探していたらO'REILLYから「PDF構造解説」という書籍が2012年に出版されていていて、248ページという適度なボリュームで良さそうだと思って読んでみました。
また、この本の特徴として、PDFコンテンツのオブジェクト間の繋がりを有向グラフで表現していて、PDFの表示の仕組みに関しても理解が進みやすくなっているように工夫されている点が良いなと感じました。
この書籍の主に3章(ファイル構造)を読んで把握できた点をまとめてみようかと思います。
環境
- macOS Catalina 10.15.7
- pdftk 2.02
PDFファイルの構造
PDFファイルはテキストデータとバイナリデータの両方を含むことができます。
組み込みのフォントや画像などのデータはバイナリデータですが、PDFファイルの構造や文章はテキストデータになっているので、テキストエディタで開くことでざっくり内容を確認することができます。
PDFファイルを開くと以下の4つの部分から構成されていることが分かります。
- ヘッダー
- ボディ
- クロスリファレンステーブル
- トレイラー

ヘッダー
最初の行では準拠するPDF仕様のバージョン(ここでは1.0)を指定します。
%PDF-1.0
ボディ
ボディ部分は一連のオブジェクト(ページ、注釈、画像、署名など)で構成され、PDFビューワーで表示されるテキストや画像などのコンテンツはボディ内のオブジェクトとして指定します。
それぞれのオブジェクトの1行目で「オブジェクト番号と世代番号、objキーワード」を指定します。最後の行で「endobjキーワード」を指定し、その間がオブジェクトのコンテンツになります。以下のオブジェクトでは <</Kids [2 0 R] /Count 1 /Type /Pages >> という辞書(後述)がコンテンツです。
1 0 obj << /Kids [2 0 R] /Count 1 /Type /Pages >> endobj
クロスリファレンステーブル
クロスリファレンステーブルでは、ボディ内の各オブジェクト毎にファイルの先頭からのバイトオフセットを保持しています。
この情報によってランダムアクセスが可能になるため、PDFビューワーはファイルの一番上から順番に処理しなくても、任意のページを高速に表示することができます。
xrefキーワードから始まり、次の行(0 7)でテーブル内のエントリ(0から始まる7つのエントリがある)を表します。 その後に続く3列の項目では、各オブジェクトの バイトオフセット、世代番号、最後の1文字で使用・未使用(fが未使用、nが使用する)を表します。
xref 0 7 0000000000 65535 f 0000000015 00000 n (以下、省略)
※最初のエントリ(0000000000 65535 f)はスペシャルエントリを表しており、使用しません。次のエントリからオブジェクト1、オブジェクト2…とそれぞれのバイトオフセットを保持します。
トレイラー
トレイラーは、クロスリファレンステーブルへのバイトオフセットを保持しており、直接アクセス可能にすることで高速にPDFファイルを開くための役割を果たしています。
trailerキーワードから始まり、次にトレーラー辞書が続きます。
トレーラー辞書は、以下2つのエントリが必須です。
/Sizeエントリ(クロスリファレンステーブルのエントリ数)/Rootエントリ(ルート要素であるドキュメントカタログのオブジェクト番号)
その後、startxrefキーワードが続き、次の行でクロスリファレンステーブルのバイトオフセット、最後行を表す%%EOFが記述されます。
trailer << /Size 7 /Root 5 0 R >> startxref 612 %%EOF
PDFファイルの基本要素
ここからはボディやトレイラーといったPDFファイルの一部ではなく、PDFファイル全体を通して使われる基本要素に関してまとめてみます。
単一の要素
整数や文字列といったそれ単体で表現される要素です。 整数や実数、文字列、名前、ブーリアン値、nullの5つがあります。
整数や実数
例: 43, 1.4142
文字列
丸括弧で囲まれると文字列になります。
例: (Lucy in the Sky)
名前
"/"から始まります。項目の識別子で、辞書のキーや様々な用途に用いられます。
例: /Kids 、 /Count 、/Size
ブーリアン値
trueキーワード または falseキーワード
null
nullキーワード指定されます。
複合的な要素
配列や辞書、ストリームの3つがあり、要素を複合的に使用します。
配列
ブランケットで囲まれると配列になります。 整数や文字列、間接参照といった要素以外にも配列や辞書も含めることができます。
例: [2 0 R 1 0 R]
上記は、1つ目の要素が 間接参照2 0 R、2つ目の要素が間接参照 1 0 R、という2つの要素から構成される長さ2の配列。
辞書
不等号を2つ続けたもの( << , >> )で囲うと辞書になります。名前から他の値に対応づけられます。配列や辞書も値にできます。
例:
<< /Kids [2 0 R] /Count 1 /Type /Pages >>
上記は、/Kids が間接参照2 0 Rを含む配列、 /Countが整数1、/Typeが名前Pages に対応づけられた辞書。
ストリーム
ストリームは、フォントや画像、図形などを格納するものです。
streamとendstreamの間に画像のバイナリデータなどの実データを指定し、辞書とセットで記述されます。
辞書には、データ長や圧縮方式といったストリームに関するメタデータを格納します。
3 0 obj << /Length 2817 >> stream (実データ) endstream endobj
参照する要素
関節参照
他のオブジェクトのリンクを作成します。
例: 1 0 R (オブジェクト番号1、世代番号0のオブジェクトへのリンクを表します。)
テキストエディタとpdftkを使ってPDFファイルを作る
ここまでのPDFファイルの構造、基本要素の内容を把握した段階で、大部分はテキストデータで記述できることが分かったので、簡単なPDFファイルをテキストエディタで作ってみました。
ただ、クロスリファレンステーブル内、トレーラー内のバイトオフセットを自分で算出して記載するのは手間だったので pdftk というコマンドラインツールを補完的に使いました。
pdftkのインストール
pdftk のインストール方法を調べたところ Homebrewを使った方法は動かなくなっているようだったので以下のパッケージファイルをダウンロードしてインストールしました。(Stackoverflow参照)
https://www.pdflabs.com/tools/pdftk-the-pdf-toolkit/pdftk_server-2.02-mac_osx-10.11-setup.pkg
テキストエディタでPDF作成
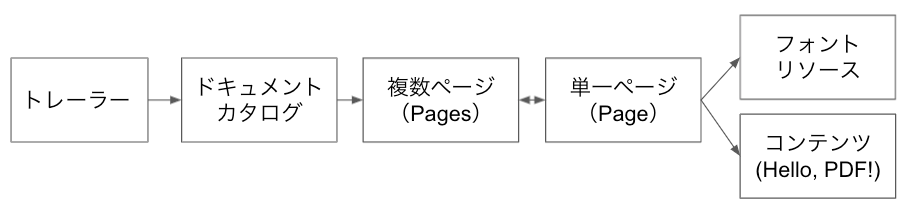
以下のグラフような構造のPDFファイルを作ってみます。
%PDF-1.0
1 0 obj
<< /Type /Pages
/Count 1
/Kids [2 0 R]
>>
endobj
2 0 obj
<< /Type /Page
/MediaBox [0 0 650 840]
/Resources 3 0 R
/Parent 1 0 R
/Contents [4 0 R]
>>
endobj
3 0 obj
<< /Font
<< /DF
<< /Type /Font
/BaseFont /Helvetica
/Subtype /Type1 >>
>>
>>
endobj
4 0 obj
<< >>
stream
1. 0. 0. 1. 10. 800. cm
BT
/DF 30. Tf
(Hello, PDF!) Tj
ET
endstream
endobj
5 0 obj
<< /Type /Catalog
/Pages 1 0 R
>>
endobj
xref
0 6
trailer
<< /Size 6
/Root 5 0 R
>>
startxref
0
%%EOF
PDFビューアーで開くと以下のような表示になります。

sample.pdfの内容
トレーラー
トレーラー辞書の/Rootには間接参照5 0 Rが対応づけられており、ルート要素であるドキュメントカタログのオブジェクト番号は5であることが分かります。
trailer << /Size 6 /Root 5 0 R >>
ドキュメントカタログ
ページツリーのオブジェクトの参照( 1 0 R )が対応づけられています。
5 0 obj << /Type /Catalog /Pages 1 0 R >> endobj
ページツリー(Pages)
オブジェクト番号2であるのページだけから構成されるページツリーです。
1 0 obj << /Type /Pages /Count 1 /Kids [2 0 R] >> endobj
ページ(Page)
用紙サイズ650x840、リソースオブジェクトの参照(3 0 R )、親ページツリーの参照( 1 0 R )、コンテンツの参照( 4 0 R )が指定されています。
2 0 obj << /Type /Page /MediaBox [0 0 650 840] /Resources 3 0 R /Parent 1 0 R /Contents [4 0 R] >> endobj
フォントリソース
名前が /DF、BaseFontが Helvetica のフォントリソースを指定しています。
3 0 obj
<< /Font
<< /DF
<< /Type /Font
/BaseFont /Helvetica
/Subtype /Type1 >>
>>
>>
endobj
コンテンツ(Hello, PDF!)
streamキーワードの次の行で、座標を右に10、上に800移動しています。また、BT(Begin Text)とET(End Text)の間で、30ポイントのフォント/DFを選択し、テキスト文字列(Hello, PDF!)を描画しています。
4 0 obj << >> stream 1. 0. 0. 1. 10. 800. cm BT /DF 30. Tf (Hello, PDF!) Tj ET endstream endobj
pdftkを使って補完
このままでもPDFファイルとして開くことはできるのですが、バイトオフセットが入っておらず任意のページにランダムアクセス可能なPDFになっていないのでpdftkを使って補完してみます。(といっても、作成したsample.pdfのページ数1はなので体感できるような表示速度の向上はありません。)
以下を実行しました。
$ pdftk sample.pdf output converted.pdf
出力されたPDFファイルをテキストエディタで開くと以下のようになり、クロスリファレンステーブルが作成され各オブジェクトのバイトオフセット、startxrefの箇所にクロスリファレンステーブルへのバイトオフセット等の情報が入っていることが確認できます。
感想
膨大な英語のドキュメントを読んでいると辛くなってくるので、日本語で書いてある資料は貴重だと思いました。
ただこの本だけでPDF仕様全体を把握できないので入門的な位置付けで捉えておいて、都度SDKのドキュメントを読んだり、仕様書を読んだりするのが良さそうです。